

Obsah
1. Od instrukční sady SSE k sadě SSE2
2. Nové datové typy podporované instrukční sadou SSE2
3. Nové instrukce přidané v rámci rozšíření instrukční sady SSE2
4. Seznam všech aritmetických instrukcí SSE2
5. Logické instrukce – rozšíření možností zavedených v rámci MMX
7. Instrukce pro porovnání skalárních hodnot nebo vektorů
8. Instrukce pro načítání či ukládání skalárů a vektorů
9. Prokládání dat, shuffling atd.
12. Detekce podpory instrukcí SSE2
13. Součty vektorů s různými počty a typy prvků
14. Součet dvojice vektorů 16×8 bitů
15. Součet dvojice vektorů 8×16 bitů
16. Součet bezznaménkových bajtů se saturací
17. Součet bajtů se znaménkem se saturací
19. Repositář s demonstračními příklady
1. Od instrukční sady SSE k sadě SSE2
Poměrně záhy po uvedení instrukční sady SSE se mnozí vývojáři začali vcelku logicky ptát, z jakého důvodu se vlastně většina nově přidaných instrukcí omezuje pouze na práci s numerickými hodnotami s jednoduchou přesností (single), když je mnoho aplikací založených na celočíselných datech (osmibitových bajtech, šestnáctibitových slovech, 32bitových slovech atd.), které by tak mohly využívat všech možností nabízených novými 128bitovými registry technologie SSE. Vývojáři pracující především na vývoji algoritmů z oblasti numerické matematiky by naopak uvítali práci s numerickými hodnotami s dvojitou přesností (double) uloženými v 64 bitech (tj. v případě 128bitových registrů by bylo možné do těchto registrů ukládat dvojice čísel s dvojitou přesností – i to by mohlo představovat poměrně významné zvýšení výpočetního výkonu).
Odpovědí na oba v podstatě protichůdné požadavky byla instrukční sada pojmenovaná jednoduše SSE2, která pochází z roku 2001 (je dobré si uvědomit, že SIMD jsou s námi na platformě x86 již dlouho). Tato instrukční sada byla zpočátku použita v mikroprocesorech Intel Pentium 4 a Intel Xeon, později se však rozšířila i na mikroprocesory firmy AMD (Athlon64, Opteron), což umožnilo její širokou adaptaci.
Technologie SSE2 vývojářům přinesla nové instrukce a samozřejmě i podstatné změny v interní struktuře vektorové výpočetní jednotky, ovšem počet registrů ani jejich bitová šířka se (alespoň prozatím) nijak nezměnila. Programátoři používající, ať již přímo či nepřímo, rozšíření instrukční sady SSE2, mohli do osmice 128bitových registrů pojmenovaných XMM0 až XMM7 ukládat celkem šest různých typů vektorů, resp. přesněji řečeno pracovat s vektory, jejichž prvky jsou šesti různých typů (formátů). Základ zůstal nezměněn – jednalo se o čtyřprvkové vektory obsahující čísla reprezentovaná ve formátu plovoucí řádové čárky, přičemž každé číslo bylo uloženo v 32 bitech (4×32=128 bitů), což odpovídá typu single/float definovanému v normě IEEE 754.
2. Nové datové typy podporované instrukční sadou SSE2
Kromě výše uvedeného typu vektoru 4×single byly v rámci SSE2 ještě zavedeny dvouprvkové vektory obsahující taktéž hodnoty reprezentované ve formátu plovoucí řádové čárky, ovšem tentokrát se jednalo o čísla uložená v 64 bitech (2×64=128) odpovídající dvojité přesnosti (double) z normy IEEE 754 (a to včetně volby zaokrouhlovacích režimů atd.).
Zbývají nám ovšem ještě čtyři další podporované datové typy. V těchto případech se jedná o vektory s celočíselnými prvky: šestnáctiprvkové vektory s osmibitovými hodnotami (zpracování obrazů), osmiprvkové vektory s šestnáctibitovými hodnotami (zpracování zvukových vzorků), čtyřprvkové vektory s 32bitovými hodnotami a konečně dvouprvkové vektory s 64bitovými celočíselnými hodnotami.

Obrázek 1: Nové typy vektorů, s kterými je nově možné nativně pracovat na mikroprocesorech podporujících technologii SSE2.
Instrukce SSE2 je možné využít i v některých oblastech numerické matematiky, i když je na tomto místě nutné říct, že přímo v SSE2 nejsou podporována čísla s rozšířenou přesností (extended), takže v některých případech může dojít při výpočtech v jednotce SSE2 (a nikoli FPU) ke kumulaci chyb ve výsledku. Nicméně kombinace instrukcí určených pro matematický koprocesor s instrukcemi určenými pro funkční jednotku SSE2 byla možná a v mnoha případech dokonce nutná, protože matematický koprocesor kromě základních aritmetických operací podporuje například i výpočet goniometrických funkcí, logaritmů atd.
3. Nové instrukce přidané v rámci rozšíření instrukční sady SSE2
Zatímco se v rozšiřující instrukční sadě SSE popsané v předchozích třech článcích nachází „pouze“ 70 nových instrukcí, byli tvůrci instrukční sady SSE2 mnohem velkorysejší, protože navrhli a posléze i implementovali hned 144 nových instrukcí, což mimochodem přibližně odpovídá počtu všech základních instrukcí procesorů x86 (pokud samozřejmě nepočítáme všechny povolené adresní režimy a další instrukce, které byly na tuto architekturu postupně „nabaleny“). Tento velký počet nových instrukcí souvisí jak s jíž zmíněnou podporou šesti nových datových typů popsaných v předchozí kapitole (včetně více než dvaceti zcela nových konverzních funkcí), tak i s novými režimy přístupu k prvkům uloženým ve vektorech a se zcela novými operacemi, které byly navrženy pro podporu algoritmů pro 3D grafiku a taktéž pro práci s videem.
Všechny instrukce, které byly přidány v rozšiřující instrukční sadě SSE2, je možné rozdělit do několika kategorií:
- Aritmetické operace prováděné s celými čísly (včetně součtu a rozdílu se saturací)
- Aritmetické operace prováděné s čísly s plovoucí řádovou čárkou (single, double)
- Logické operace (některé jsou prováděny pro všech 128 bitů)
- Bitové posuny prvků o různé bitové šířce
- Porovnávací (komparační, relační) operace
- Konverzní funkce
- Konverze prvků uložených ve vektorech (zvýšení či snížení bitové šířky, shuffling apod.)
- Načítání a ukládání dat do operační paměti
- Řízení vyrovnávací paměti (cache)
O těchto instrukcích se zmíníme v navazující kapitole.
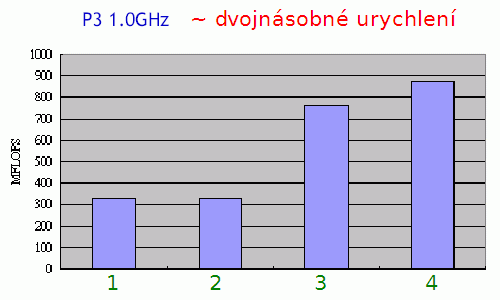
Obrázek 2: Ukázka urychlení operace součtu 1024 číselných prvků reprezentovaných ve formátu s plovoucí řádovou čárkou. Celkem byly použity čtyři algoritmy pro součet:
1 – využití instrukcí FPU
2 – využití instrukcí FPU s rozbalením smyčky
3 – využití vektorových operací SSE/SSE2
4 – využití vektorových operací SSE/SSE2 s rozbalením smyčky
4. Seznam všech aritmetických instrukcí SSE2
Podobně jako u již dříve popsaných rozšiřujících instrukčních sad MMX, 3DNow! a SSE se SIMD instrukcemi, tvoří i u instrukční sady SSE2 nejpodstatnější část nové instrukce určené pro provádění aritmetických operací nad vektory prvků různých datových typů. Všechny nové operace implementované v rámci SSE2 jsou vypsány v následující tabulce. Ve třetím sloupci je naznačeno, jaké vektory jsou danou operací zpracovávány, přičemž první číslo znamená počet prvků vektoru, za nímž následuje bitová šířka jednotlivých prvků:
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Saturace? | Poznámka |
|---|---|---|---|---|---|---|
| 1 | ADDPD | součet | 2×64bit | double | × | |
| 2 | ADDSD | součet | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 3 | SUBPD | rozdíl | 2×64bit | double | × | |
| 4 | SUBSD | rozdíl | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 5 | MULPD | součin | 2×64bit | double | × | |
| 6 | MULSD | součin | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 7 | DIVPD | podíl | 2×64bit | double | × | |
| 8 | DIVSD | podíl | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 9 | PADDB | součet | 16×8bit | integer | ne | |
| 10 | PADDW | součet | 8×16bit | integer | ne | |
| 11 | PADDD | součet | 4×32bit | integer | ne | |
| 12 | PADDQ | součet | 2×64bit | integer | ne | |
| 13 | PADDSB | součet | 16×8bit | integer | ano | |
| 14 | PADDSW | součet | 8×16bit | integer | ano | |
| 15 | PADDUSB | součet | 16×8bit | unsigned | ano | |
| 16 | PADDUSW | součet | 8×16bit | unsigned | ano | |
| 17 | PSUBB | rozdíl | 16×8bit | integer | ne | |
| 18 | PSUBW | rozdíl | 8×16bit | integer | ne | |
| 19 | PSUBD | rozdíl | 4×32bit | integer | ne | |
| 20 | PSUBQ | rozdíl | 2×64bit | integer | ne | |
| 21 | PSUBSB | rozdíl | 16×8bit | integer | ano | |
| 22 | PSUBSW | rozdíl | 8×16bit | integer | ano | |
| 23 | PSUBUSB | rozdíl | 16×8bit | unsigned | ano | |
| 24 | PSUBUSW | rozdíl | 8×16bit | unsigned | ano | |
| 25 | MAXPD | maximu | 2×64bit | double | × | |
| 26 | MAXSD | maximum | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 27 | MINPD | minimum | 2×64bit | double | × | |
| 28 | MINSD | minimum | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 29 | PMADDWD | součin/add | 8×16bit | integer | × | |
| 30 | PMULHW | součin | 8×16bit | integer | × | vrací vektor horních 16 bitů výsledků |
| 31 | PMULLW | součin | 8×16bit | integer | × | vrací vektor dolních 16 bitů výsledků |
| 32 | PMULUDQ | součin | 4×32bit | integer | × | 64 bitový výsledek pro každý součin |
| 33 | RCPPS | převrácená hodnota | 4×32bit | single | × | aproximace |
| 34 | RCPSS | převrácená hodnota | 4×32bit | single | × | operace provedena jen s pravým prvkem vektorů |
| 35 | SQRTPD | druhá odmocnina | 2×64bit | double | × | |
| 36 | SQRTSD | druhá odmocnina | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
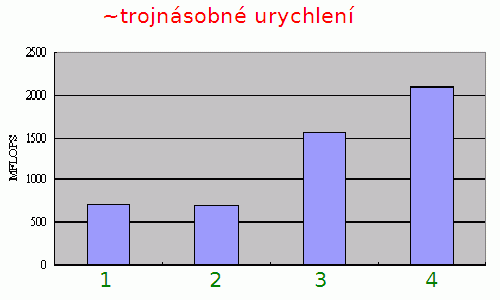
Obrázek 3: Ukázka urychlení operace výpočtu skalárního součinu pro 1024 trojrozměrných vektorů. Prvky vektorů jsou opět reprezentovány ve formátu s plovoucí řádovou čárkou. Celkem byly použity čtyři algoritmy pro součet:
1 – využití instrukcí FPU
2 – využití instrukcí FPU s rozbalením smyčky
3 – využití vektorových operací SSE/SSE2
4 – využití vektorových operací SSE/SSE2 s rozbalením smyčky
Důvod, proč ze došlo k většímu urychlení při použití SSE/SSE2 je jednoduchý: s jednou načtenými daty (vektory) se provádělo větší množství operací, takže se zde v menší míře projevila latence operačních pamětí a další externí vlivy. Sice je možné najít i algoritmy, u nichž je dosaženo ještě většího urychlení výpočtů, ale v praxi je zhruba trojnásobné urychlení (podobně jako na tomto grafu) považováno za poměrně velký úspěch.
5. Logické instrukce – rozšíření možností zavedených v rámci MMX
V instrukční sadě SSE2 můžeme kromě aritmetických instrukcí najít i nové logické instrukce a taktéž instrukce určené pro provádění logických či aritmetických posunů. Ve skutečnosti se vlastně jedná o pouhé rozšíření stávajících instrukcí MMX takovým způsobem, aby bylo možné pracovat s novými 128bitovými vektory, popř. s daty uloženými v operační paměti v bloku šestnácti bajtů (16×8=128 bitů). Nejprve si popišme instrukce pro aritmetické a logické posuny. Ty dokážou pracovat s celočíselnými hodnotami o velikosti 16, 32, 64 či 128 bitů, tj. každá část vektoru se posouvá zvlášť (je tedy například velký rozdíl mezi posunem jednoho 128bitového čísla a dvojice 64bitových čísel). Při logických posunech se do nového bitu nasouvá vždy logická nula (nikoli příznak carry), u aritmetických posunů se opakuje hodnota původního nejvyššího bitu, tj. instrukce pracují přesně tak, jak to programátoři očekávají:
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Poznámka |
|---|---|---|---|---|---|
| 1 | PSLLDQ | logický posun doleva | 1×128bitů | integer | |
| 2 | PSLLQ | logický posun doleva | 2×64bitů | integer | |
| 3 | PSLLD | logický posun doleva | 4×32bitů | integer | |
| 4 | PSLLW | logický posun doleva | 8×16bitů | integer | |
| 5 | PSRLDQ | logický posun doprava | 1×128bitů | integer | |
| 6 | PSRLQ | logický posun doprava | 2×64bitů | integer | |
| 7 | PSRLD | logický posun doprava | 4×32bitů | integer | |
| 8 | PSRLW | logický posun doprava | 8×16bitů | integer | |
| 9 | PSRAD | aritmetický posun doprava | 4×32bitů | integer | |
| 10 | PSRAW | aritmetický posun doprava | 8×16bitů | integer |
Následuje seznam instrukcí určených pro provádění logických operací nad vektory různé délky. V některých případech (PAND, POR, PXOR) se jedná o „pouhé“ rozšíření původních MMX instrukcí takovým způsobem, aby tyto instrukce mohly pracovat se 128bitovými vektory. Dokonce i operační kódy instrukcí zůstávají stejné, ovšem v případě SSE2 je před vlastním instrukčním kódem uveden prefix 0×66, takže jsou instrukce o jeden bajt delší (to ostatně platí i pro aritmetické operace popsané o několik odstavců výše):
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Poznámka |
|---|---|---|---|---|---|
| 1 | PAND | and | 1×128 bitů | integer | |
| 2 | PANDN | not and | 1×128 bitů | integer | první operand je negován |
| 3 | POR | or | 1×128 bitů | integer | |
| 4 | PXOR | xor | 1×128 bitů | integer | |
| 5 | ANDPD | and | 2×64 bitů | double | |
| 6 | ORPD | or | 2×64 bitů | double | |
| 7 | XORPD | xor | 2×64 bitů | double | |
| 8 | ANDNPD | not and | 2×64 bitů | double | první operand je negován |
| 9 | ANDNPS | not and | 4×32 bitů | single | první operand je negován |
6. Instrukce pro konverzi dat
Při implementaci mnoha typů algoritmů, především pak při zpracování obrazových a zvukových datových toků, se mnohdy programátoři dostanou do situace, kdy potřebují zkonvertovat data do jiného formátu, než v jakém byla původně uložena. Pro tyto účely jsou v instrukční sadě SSE2 k dispozici dvě desítky konverzních instrukcí začínajících prefixem CVT, vypsaných v tabulce pod tímto odstavcem. Opět platí, že konverze jsou prováděny paralelně:
| # | Instrukce | Konverze z… | Konverze do… |
|---|---|---|---|
| 1 | CVTDQ2PD | 2×32bitový integer | 2×64bitový double |
| 2 | CVTDQ2PS | 4×32bitový integer | 4×32bitový single |
| 3 | CVTPD2PI | 2×64bitový double | 2×32bitový integer v MMX registru |
| 4 | CVTPD2DQ | 2×64bitový double | 2×32bitový integer ve spodní polovině MMX registru |
| 5 | CVTPD2PS | 2×64bitový double | 2×32bitový single ve spodní polovině MMX registru |
| 6 | CVTPI2PD | 2×32bitový integer | 2×32bitový single ve spodní polovině MMX registru |
| 7 | CVTPS2DQ | 4×32bitový single | 4×32bitový integer |
| 8 | CVTPS2PD | 2×32bitový single | 2×64bitový double |
| 9 | CVTSD2SI | 1×64bitový double | 1×32bitový integer v pracovním registru (CPU) |
| 10 | CVTTPD2PI | 2×64bitový double | 2×32bitový integer (odseknutí desetinné části) |
| 11 | CVTTPD2DQ | 2×64bitový double | 2×32bitový integer (odseknutí desetinné části) |
| 12 | CVTTPS2DQ | 4×32bitový single | 4×32bitový integer (odseknutí desetinné části) |
| 13 | CVTTPS2PI | 2×32bitový single | 2×32bitový integer (odseknutí desetinné části) v MMX registru |
| 14 | CVTTSD2SI | 1×64bitový double | 1×32bitový integer (odseknutí desetinné části) v pracovním registru |
| 15 | CVTTSS2SI | 1×32bitový single | 1×32bitový integer (odseknutí desetinné části) v pracovním registru |
| 16 | CVTSI2SD | 1×32bitový integer | 1×64bitový double |
| 17 | CVTSI2SS | 1×32bitový integer | 1×32bitový single |
| 18 | CVTSD2SS | 1×64bitový double | 1×32bitový single (horní polovina registru se nemění) |
| 19 | CVTSS2SD | 1×32bitový single | 1×64bitový double |
| 20 | CVTSS2SI | 1×32bitový single | 1×32bitový integer v pracovním registru (CPU) |

Obrázek 28: Univerzální konverzní funkce PSHUF byla v instrukční sadě SSE2 rozšířena tak, aby dokázala pracovat i se 128bitovými registry (existuje několik variant této instrukce, další varianty byly zavedeny až v SSE3 atd).
7. Instrukce pro porovnání skalárních hodnot nebo vektorů
Dalších několik instrukcí dokáže porovnat vektory různých typů a buď nastavit prvky výsledného vektoru či přímo ovlivnit příznakový registru EFLAGS (což je poměrně užitečná novinka). Jedná se o následující instrukce:
| # | Instrukce | Prováděná operace | Příznaky uloženy do |
|---|---|---|---|
| 1 | CMP??SD | porovnání dvou hodnot typu double (dolní polovina registru) | registr XMM |
| 2 | CMP??PD | porovnání dvou registrů s hodnotami double | registr XMM |
| 3 | COMISD | porovnání dvou hodnot typu double (dolní polovina registru) | příznakový registr EFLAGS |
| 4 | UCOMISD | porovnání dvou hodnot typu double (dolní polovina registru) | příznakový registr EFLAGS |
| 5 | PCMP??B | porovnání vektorů s 8bitovými integery | registr XMM |
| 6 | PCMP??W | porovnání vektorů se 16bitovými integery | registr XMM |
| 7 | PCMP??D | porovnání vektorů s 32bitovými integery | registr XMM |
Většina assemblerů rozpoznává následující znaky, kterými lze nahradit otazníky v názvu instrukce. Tyto znaky specifikují způsob porovnání a v instrukční slovu jsou uloženy ve zvláštním bajtu (jedná se vlastně o třetí operand těchto instrukcí):
| # | Znaky | Význam |
|---|---|---|
| 1 | EQ | rovnost |
| 2 | LT | menší než |
| 3 | LE | menší nebo rovno |
| 4 | NE | nerovnost |
| 5 | NLT | není menší než (tedy větší nebo rovno) |
| 6 | NLE | větší než |
| 7 | ORD | porovnatelné hodnoty |
| 8 | UNORD | neporovnatelné hodnoty |
8. Instrukce pro načítání či ukládání skalárů a vektorů
Další část instrukcí slouží pro načtení či naopak pro uložení skalárních hodnot z/do registrů XMM. Některé z těchto instrukcí jsme již viděli ve variantě pro SSE, další jsou nově zavedené právě pro SSE2:
Nově jsou přidány instrukce pro přenosy bez použití cache, což může být velmi užitečná optimalizace (samozřejmě v závislosti na řešeném problému). A poslední dvě instrukce pracují s takzvanými maskami. Těmito instrukcemi se budeme zabývat v samostatné kapitole.
9. Prokládání dat, shuffling atd.
Nejzajímavější změny, které byly v instrukční sadě SSE2 provedeny, se týkají instrukcí pro prokládání dat ve vektorových registrech, pro přesuny prvků (shuffling) v rámci registrů atd. Těchto instrukcí je nyní celá řada a doplňují tak původní trojici instrukcí UNPCKHPS, UNPCKLPS a SHUFPS, které jsme si popsali minule. Tyto instrukce sice mohou být poněkud složitější na pochopení (a příslušný vzor nerozpoznají ani mnohé překladače), ale jsou velmi užitečné:
| # | Instrukce | Prováděná operace |
|---|---|---|
| 1 | MOVQ | přenos 64bitové hodnoty, horní polovina cílového XMM registru se vynuluje |
| 2 | MOVSD | přenos 64bitové hodnoty, horní polovina cílového registru se nemusí změnit |
| 3 | MOVAPD | přenos 128bitové hodnoty, která musí být v paměti zarovnána |
| 4 | MOVUPD | přenos 128bitové hodnoty, která nemusí být v paměti zarovnána |
| 5 | MOVHPD | přenos horních 64 bitů XMM registru |
| 6 | MOVLPD | přenos dolních 64 bitů XMM registru |
| 7 | MOVDQ2Q | přenos 64bitové hodnoty mezi XMM a MMX registry |
| 8 | MOVQ2DQ | přenos 64bitové hodnoty mezi XMM a MMX registry |
| 9 | MOVNTPD | uložení 128 bitů do paměti bez použití cache |
| 10 | MOVNTDQ | uložení 128 bitů do paměti bez použití cache |
| 11 | MOVNTI | přenos 32bitové hodnoty bez použití cache |
| 12 | MASKMOVDQU | uložení vybraných bajtů z XMM registru do paměti |
| 13 | PMOVMSKB | vytvoření masky na základě znaménkových bitů z každého bajtu XMM registru |
| # | Instrukce | Prováděná operace |
|---|---|---|
| 1 | PSHUFD | shuffle, s 32bitovými prvky |
| 2 | PSHUFHW | shuffle, se 16bitovými prvky |
| 3 | PSHUFLW | shuffle, se 16bitovými prvky |
| 4 | UNPCKHPD | rozbalení prvků, 64bitové hodnoty v horních 64bitech |
| 5 | UNPCKLPD | rozbalení prvků, 64bitové hodnoty v dolních 64bitech |
| 6 | PUNPCKHBW | rozbalení a proložení prvků, 8 osmibitových hodnot |
| 7 | PUNPCKHWD | rozbalení a proložení prvků, 4 16bitové hodnoty |
| 8 | PUNPCKHDQ | rozbalení a proložení prvků, 2 32bitové hodnoty |
| 9 | PUNPCKHQDQ | rozbalení a proložení 64bitových hodnot |
| 10 | PUNPCKLBW | obdoba PUNPCKHBW, ale pro spodních 64 bitů vektorového registru |
| 11 | PUNPCKLWD | obdoba PUNPCKHWD, ale pro spodních 64 bitů vektorového registru |
| 12 | PUNPCKLDQ | obdoba PUNPCKHDQ, ale pro spodních 64 bitů vektorového registru |
| 13 | PUNPCKLQDQ | obdoba PUNPCKHQDQ, ale pro spodních 64 bitů vektorového registru |
| 14 | PACKSSDW | převod 32bitových hodnot do 16bitové hodnoty se saturací (signed) |
| 15 | PACKSSWB | převod 16bitových hodnot do osmibitové hodnoty se saturací (signed) |
| 16 | PACKUSWB | převod 16bitových hodnot do osmibitové hodnoty se saturací (unsigned) |
10. Řízení cache
Posledních několik instrukcí slouží pro řízení cache; takže je například možné vyprázdnění cache před prováděním složitějších výpočtů na stejným (větším) polem atd.:
| # | Instrukce | Prováděná operace |
|---|---|---|
| 1 | CLFLUSH | vyprázdnění cache |
| 2 | LFENCE | zajištění, že všechny instrukce před touto instrukcí budou dokončeny (bariéra) |
| 3 | MFENCE | zajištění, že všechny operace čtení a zápise před touto instrukcí budou dokončeny |
11. Praktická část
Podobně jako v předchozích článcích se i dnes vydáme do temných zákoutí assembleru. Ukážeme si několik příkladů využití vybraných instrukcí ze sady SSE2. Ovšem ty složitější (a nutno dodat, že i zajímavější) instrukce budou ukázány příště, kdy téma SSE2 dokončíme. Všechny dále uvedené demonstrační příklady jsou napsány pro Netwide Assembler (NASM) a jsou přeložitelné a spustitelné v Linuxu.
12. Detekce podpory instrukcí SSE2
Začneme již klasickým příkladem – využitím instrukce CPUID pro zjištění, zda mikroprocesor vůbec podporuje instrukce SSE2. Většina mikroprocesorů x86, resp. x86–64 vyrobená v posledních dvaceti letech by měla plně podporovat většinu již popsaných SIMD rozšíření, tedy MMX, SSE i SSE2 (ovšem nikoli 3DNow!, což však nevadí). Povšimněte si, že podpora SSE2 je vyjádřena příznakovým bitem, jehož index je o jedničku vyšší, než index příznaku podpory SSE:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
mmx_supported:
db 10, "MMX supported"
mmx_supported_length equ $ - mmx_supported
sse_supported:
db 10, "SSE supported"
sse_supported_length equ $ - sse_supported
sse2_supported:
db 10, "SSE2 supported"
sse2_supported_length equ $ - sse2_supported
;-----------------------------------------------------------------------------
section .bss
id_string: resb 8
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
; ziskani indexu nejvyssi volatelne funkce CPUID
xor eax, eax ; nulta kategorie
cpuid
mov edx, eax ; hodnota, ktera se ma vytisknout
mov ebx, hex_message ; buffer, ktery se zaplni hexa cislicemi
call hex2string ; zavolani prislusne subrutiny
print_string hex_message, hex_message_length ; tisk hexadecimalni hodnoty
; test podpory SSE
mov eax, 1 ; prvni kategorie
cpuid
mov ebx, hex_message ; buffer, ktery se zaplni hexa cislicemi
call hex2string ; zavolani prislusne subrutiny
print_string hex_message, hex_message_length ; tisk hexadecimalni hodnoty
; vypis CPU ID
xor eax, eax ; nulta kategorie
cpuid
mov [id_string], ebx ; prvni ctyri znaky ID
mov [id_string+4], edx ; dalsi ctyri znaky ID
mov [id_string+8], ecx ; posledni ctyri znaky ID
print_string id_string, 12 ; tisk 12 znaku CPU ID
mov eax, 1 ; prvni kategorie
cpuid ; naplneni EDX a ECX
bt edx, 23 ; test bitu cislo 23: podpora MMX
jnc mmx_not_supported
print_string mmx_supported, mmx_supported_length
mmx_not_supported:
mov eax, 1 ; prvni kategorie
cpuid ; naplneni EDX a ECX
bt edx, 25 ; test bitu cislo 25: podpora SSE
jnc sse_not_supported
print_string sse_supported, sse_supported_length
sse_not_supported:
mov eax, 1 ; prvni kategorie
cpuid ; naplneni EDX a ECX
bt edx, 26 ; test bitu cislo 25: podpora SSE2
jnc sse2_not_supported
print_string sse2_supported, sse2_supported_length
sse2_not_supported:
exit ; ukonceni procesu
%include "hex2string.asm"
Výsledky mohou vypadat například takto:
00000020 BFEBFBFF GenuineIntel MMX supported SSE supported SSE2 supported
13. Součty vektorů s různými počty a typy prvků
V rámci instrukční sady SSE2 se rozšířily možnosti instrukcí provádějících vektorové součty. Situace je vlastně velmi jednoduchá – tyto instrukce existovaly již v sadě MMX, kde pracovaly s 64bitovými vektory. V SSE2 došlo k rozšíření těchto instrukcí takovým způsobem, že bylo možné použít i registry XMM s dvojnásobnou šířkou a tím pádem i s vektory, které obsahují dvojnásobný počet prvků. Čistě teoreticky tak lze dosáhnout dvojnásobného výpočetního výkonu u těchto operací (v praxi to samozřejmě bude méně):
| 1 | PADDB | součet | 16×8bit | integer | ne | |
| 2 | PADDW | součet | 8×16bit | integer | ne | |
| 3 | PADDD | součet | 4×32bit | integer | ne | |
| 4 | PADDQ | součet | 2×64bit | integer | ne | |
| 5 | PADDSB | součet | 16×8bit | integer | ano | |
| 6 | PADDSW | součet | 8×16bit | integer | ano | |
| 7 | PADDUSB | součet | 16×8bit | unsigned | ano | |
| 8 | PADDUSW | součet | 8×16bit | unsigned | ano |
Zajímavé bude zjistit, jak se vlastně liší kódování stejných instrukcí ze sady MMX a SSE2. To, o kterou instrukci se jedná, se zjistí z jejich parametrů:
section .text
paddb mm0, mm1
paddb xmm0, xmm1
paddsb mm0, mm1
paddsb xmm0, xmm1
paddusb mm0, mm1
paddusb xmm0, xmm1
paddw mm0, mm1
paddw xmm0, xmm1
paddsw mm0, mm1
paddsw xmm0, xmm1
paddusw mm0, mm1
paddusw xmm0, xmm1
paddd mm0, mm1
paddd xmm0, xmm1
paddq mm0, mm1
paddq xmm0, xmm1
Z výsledků je patrné, že nové SSE2 instrukce pouze přidávají prefixový bajt 0×66, zbytek instrukčního slova je shodný:
1 [bits 32]
2
3 ;-----------------------------------------------------------------------------
4 section .text
5 00000000 0FFCC1 paddb mm0, mm1
6 00000003 660FFCC1 paddb xmm0, xmm1
7
8 00000007 0FECC1 paddsb mm0, mm1
9 0000000A 660FECC1 paddsb xmm0, xmm1
10
11 0000000E 0FDCC1 paddusb mm0, mm1
12 00000011 660FDCC1 paddusb xmm0, xmm1
13
14 00000015 0FFDC1 paddw mm0, mm1
15 00000018 660FFDC1 paddw xmm0, xmm1
16
17 0000001C 0FEDC1 paddsw mm0, mm1
18 0000001F 660FEDC1 paddsw xmm0, xmm1
19
20 00000023 0FDDC1 paddusw mm0, mm1
21 00000026 660FDDC1 paddusw xmm0, xmm1
22
23 0000002A 0FFEC1 paddd mm0, mm1
24 0000002D 660FFEC1 paddd xmm0, xmm1
25
26 00000031 0FD4C1 paddq mm0, mm1
27 00000034 660FD4C1 paddq xmm0, xmm1
28
14. Součet dvojice vektorů 16×8 bitů
V dnešním druhém demonstračním příkladu je ukázán součet dvou šestnácti prvkových vektorů s hodnotami typu byte. Nejprve načteme dvojici vektorů do SSE registrů XMM0 a XMM1. Následně provedeme součet obou vektorů instrukcí PADDB, která provádí součet bajt po bajtu (tedy paralelně se sečte šestnáct hodnot prvního vektoru se šestnácti hodnotami vektoru druhého). V případě, že výsledek přesáhne hodnotu 255, dojde k přetečení:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
align 16
sse_val_1 db 0x00, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60, 0x70, 0x80, 0x90, 0xa0, 0xb0, 0xc0, 0xd0, 0xe0, 0xf0
sse_val_2 db 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80,
;-----------------------------------------------------------------------------
section .bss
sse_tmp resb 16
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov ebx, sse_val_1
movaps xmm0, [ebx] ; nacteni prvni hodnoty do registru XMM0
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
mov ebx, sse_val_2
movaps xmm1, [ebx] ; nacteni druhe hodnoty do registru XMM1
print_sse_reg_as_hex xmm1 ; tisk hodnoty registru XMM1
paddb xmm0, xmm1 ; soucet vektoru po bajtech
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
exit ; ukonceni procesu
%include "hex2string.asm"
Výsledky ukazují, že dochází k přetečení k rámci jednotlivých bajtů, ovšem nikoli k přenosu hodnoty do vyšších bajtů:
vektor1: F0 E0 D0 C0 B0 A0 90 80 70 60 50 40 30 20 10 00
vektor2: 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80
-----------------------------------------------
výsledek: 70 60 50 40 30 20 10 00 F0 E0 D0 C0 B0 A0 90 80
15. Součet dvojice vektorů 8×16 bitů
Podobným způsobem, ovšem s využitím instrukce PADDW namísto PADDB, můžeme provést součet osmi šestnáctibitových prvků vektorů. Samotný zdrojový kód příkladu se změní jen nepatrně (náhrada jediné instrukce), ovšem výsledky budou zcela odlišné:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
align 16
sse_val_1 db 0x00, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60, 0x70, 0x80, 0x90, 0xa0, 0xb0, 0xc0, 0xd0, 0xe0, 0xf0
sse_val_2 db 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80,
;-----------------------------------------------------------------------------
section .bss
sse_tmp resb 16
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov ebx, sse_val_1
movaps xmm0, [ebx] ; nacteni prvni hodnoty do registru XMM0
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
mov ebx, sse_val_2
movaps xmm1, [ebx] ; nacteni druhe hodnoty do registru XMM1
print_sse_reg_as_hex xmm1 ; tisk hodnoty registru XMM1
paddw xmm0, xmm1 ; soucet vektoru po slovech
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
exit ; ukonceni procesu
%include "hex2string.asm"
Ze zobrazených výsledků je patrné, že nyní dochází k přenosu do vyšších bajtů, ale vždy jen v hranici 16bitových slov:
vektor1: F0E0 D0C0 B0A0 9080 7060 5040 3020 1000
vektor2: 8080 8080 8080 8080 8080 8080 8080 8080
---------------------------------------
výsledek: 7160 5140 3120 1100 F0E0 D0C0 B0A0 9080
přenosy: ^ ^ ^ ^
16. Součet bezznaménkových bajtů se saturací
V multimediálních a DSP aplikacích je velmi užitečná i možnost sčítat a odčítat hodnoty se saturací namísto přetečení. Tuto operaci si můžeme ukázat na součtu bezznaménkových bajtů (resp. přesněji řečeno vektorů se šestnácti osmibitovými prvky), přičemž použijeme instrukci PADDUSB. Tato instrukce provádí součet se saturací, přičemž se sčítané hodnoty považují za osmibitové hodnoty bez znaménka (unsigned). Výsledky tedy nepřetečou přes hodnotu 0×FF (což si ověříme):
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
align 16
sse_val_1 db 0x00, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60, 0x70, 0x80, 0x90, 0xa0, 0xb0, 0xc0, 0xd0, 0xe0, 0xf0
sse_val_2 db 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80,
;-----------------------------------------------------------------------------
section .bss
sse_tmp resb 16
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov ebx, sse_val_1
movaps xmm0, [ebx] ; nacteni prvni hodnoty do registru XMM0
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
mov ebx, sse_val_2
movaps xmm1, [ebx] ; nacteni druhe hodnoty do registru XMM1
print_sse_reg_as_hex xmm1 ; tisk hodnoty registru XMM1
paddusb xmm0, xmm1 ; soucet vektoru po bajtech se saturaci
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
exit ; ukonceni procesu
%include "hex2string.asm"
Z výsledků je skutečně patrné, že součty, které přesahují hodnotu 255, jsou saturovány právě na této hodnotě (0×ff):
vektor1: F0 E0 D0 C0 B0 A0 90 80 70 60 50 40 30 20 10 00
vektor2: 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80
-----------------------------------------------
výsledek: FF FF FF FF FF FF FF FF F0 E0 D0 C0 B0 A0 90 80
17. Součet bajtů se znaménkem se saturací
V některých případech, například při zpracování audio vzorků, se nepracuje s hodnotami bez znaménka (unsigned), ale naopak s hodnotami se znaménkem (signed). V případě bajtů budou takové hodnoty saturovány v rozsahu –128 až 127, což si ověříme na tomto příkladu:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
align 16
sse_val_1 db 0x00, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60, 0x70, 0x80, 0x90, 0xa0, 0xb0, 0xc0, 0xd0, 0xe0, 0xf0
sse_val_2 db 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80,
;-----------------------------------------------------------------------------
section .bss
sse_tmp resb 16
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov ebx, sse_val_1
movaps xmm0, [ebx] ; nacteni prvni hodnoty do registru XMM0
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
mov ebx, sse_val_2
movaps xmm1, [ebx] ; nacteni druhe hodnoty do registru XMM1
print_sse_reg_as_hex xmm1 ; tisk hodnoty registru XMM1
paddsb xmm0, xmm1 ; soucet vektoru po bajtech se saturaci
print_sse_reg_as_hex xmm0 ; tisk hodnoty registru XMM0
exit ; ukonceni procesu
%include "hex2string.asm"
Výsledky v případě, že sčítáme hodnoty s konstantami 0×80 (tedy nejmenší reprezentovatelnou hodnotou v oboru bajtů se znaménkem):
vektor1: F0 E0 D0 C0 B0 A0 90 80 70 60 50 40 30 20 10 00
vektor2: 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80 80
-----------------------------------------------
výsledek: 80 80 80 80 80 80 80 80 F0 E0 D0 C0 B0 A0 90 80
Saturace na nejvyšší možné kladné hodnotě 127 (0×7F) vypadá takto:

vektor1: F0 E0 D0 C0 B0 A0 90 80 70 60 50 40 30 20 10 00
vektor2: 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F 7F
-----------------------------------------------
výsledek: 6F 5F 4F 3F 2F 1F 0F FF 7F 7F 7F 7F 7F 7F 7F 7F
18. Obsah navazujícího článku
V dalším článku se zaměříme na komplikovanější instrukce, které byly zavedeny v sadě SSE2. Ukážeme si také praktičtěji zaměřené příklady, například rychlý výpočet skalárního součinu, což nemusí být tak triviální úloha, jak by se mohlo na první pohled zdát (na druhou stranu se tento výpočet používá velmi často, jako jedna z variant zjištění podobnosti dvou vektorů v mnoha „AI“ algoritmech).
19. Repositář s demonstračními příklady
Demonstrační příklady napsané v assembleru, které jsou určené pro překlad s využitím assembleru NASM, byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/8bit-fame. Jednotlivé demonstrační příklady si můžete v případě potřeby stáhnout i jednotlivě bez nutnosti klonovat celý (dnes již poměrně rozsáhlý) repositář:
20. Odkazy na Internetu
- The Intel 8088 Architecture and Instruction Set
https://people.ece.ubc.ca/~edc/464/lectures/lec4.pdf - x86 Opcode Structure and Instruction Overview
https://pnx.tf/files/x86_opcode_structure_and_instruction_overview.pdf - x86 instruction listings (Wikipedia)
https://en.wikipedia.org/wiki/X86_instruction_listings - x86 assembly language (Wikipedia)
https://en.wikipedia.org/wiki/X86_assembly_language - Intel Assembler (Cheat sheet)
http://www.jegerlehner.ch/intel/IntelCodeTable.pdf - 25 Microchips That Shook the World
https://spectrum.ieee.org/tech-history/silicon-revolution/25-microchips-that-shook-the-world - Chip Hall of Fame: MOS Technology 6502 Microprocessor
https://spectrum.ieee.org/tech-history/silicon-revolution/chip-hall-of-fame-mos-technology-6502-microprocessor - Chip Hall of Fame: Intel 8088 Microprocessor
https://spectrum.ieee.org/tech-history/silicon-revolution/chip-hall-of-fame-intel-8088-microprocessor - Jak se zrodil procesor?
https://www.root.cz/clanky/jak-se-zrodil-procesor/ - Apple II History Home
http://apple2history.org/ - The 8086/8088 Primer
https://www.stevemorse.org/8086/index.html - flat assembler: Assembly language resources
https://flatassembler.net/ - FASM na Wikipedii
https://en.wikipedia.org/wiki/FASM - Fresh IDE FASM inside
https://fresh.flatassembler.net/ - MS-DOS Version 4.0 Programmer's Reference
https://www.pcjs.org/documents/books/mspl13/msdos/dosref40/ - DOS API (Wikipedia)
https://en.wikipedia.org/wiki/DOS_API - Bit banging
https://en.wikipedia.org/wiki/Bit_banging - IBM Basic assembly language and successors (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors - X86 Assembly/Bootloaders
https://en.wikibooks.org/wiki/X86_Assembly/Bootloaders - Počátky grafiky na PC: grafické karty CGA a Hercules
https://www.root.cz/clanky/pocatky-grafiky-na-pc-graficke-karty-cga-a-hercules/ - Co mají společného Commodore PET/4000, BBC Micro, Amstrad CPC i grafické karty MDA, CGA a Hercules?
https://www.root.cz/clanky/co-maji-spolecneho-commodore-pet-4000-bbc-micro-amstrad-cpc-i-graficke-karty-mda-cga-a-hercules/ - Karta EGA: první použitelná barevná grafika na PC
https://www.root.cz/clanky/karta-ega-prvni-pouzitelna-barevna-grafika-na-pc/ - RGB Classic Games
https://www.classicdosgames.com/ - Turbo Assembler (Wikipedia)
https://en.wikipedia.org/wiki/Turbo_Assembler - Microsoft Macro Assembler
https://en.wikipedia.org/wiki/Microsoft_Macro_Assembler - IBM Personal Computer (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Personal_Computer - Intel 8251
https://en.wikipedia.org/wiki/Intel_8251 - Intel 8253
https://en.wikipedia.org/wiki/Intel_8253 - Intel 8255
https://en.wikipedia.org/wiki/Intel_8255 - Intel 8257
https://en.wikipedia.org/wiki/Intel_8257 - Intel 8259
https://en.wikipedia.org/wiki/Intel_8259 - Support/peripheral/other chips – 6800 family
http://www.cpu-world.com/Support/6800.html - Motorola 6845
http://en.wikipedia.org/wiki/Motorola_6845 - The 6845 Cathode Ray Tube Controller (CRTC)
http://www.tinyvga.com/6845 - CRTC operation
http://www.6502.org/users/andre/hwinfo/crtc/crtc.html - The 6845 Cathode Ray Tube Controller (CRTC)
http://www.tinyvga.com/6845 - Motorola 6845 and bitwise graphics
https://retrocomputing.stackexchange.com/questions/10996/motorola-6845-and-bitwise-graphics - IBM Monochrome Display Adapter
http://en.wikipedia.org/wiki/Monochrome_Display_Adapter - Color Graphics Adapter
http://en.wikipedia.org/wiki/Color_Graphics_Adapter - Color Graphics Adapter and the Brown color in IBM 5153 Color Display
https://www.aceinnova.com/en/electronics/cga-and-the-brown-color-in-ibm-5153-color-display/ - The Modern Retrocomputer: An Arduino Driven 6845 CRT Controller
https://hackaday.com/2017/05/14/the-modern-retrocomputer-an-arduino-driven-6845-crt-controller/ - flat assembler: Assembly language resources
https://flatassembler.net/ - FASM na Wikipedii
https://en.wikipedia.org/wiki/FASM - Fresh IDE FASM inside
https://fresh.flatassembler.net/ - MS-DOS Version 4.0 Programmer's Reference
https://www.pcjs.org/documents/books/mspl13/msdos/dosref40/ - DOS API (Wikipedia)
https://en.wikipedia.org/wiki/DOS_API - IBM Basic assembly language and successors (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors - X86 Assembly/Arithmetic
https://en.wikibooks.org/wiki/X86_Assembly/Arithmetic - Art of Assembly – Arithmetic Instructions
http://oopweb.com/Assembly/Documents/ArtOfAssembly/Volume/Chapter6/CH06–2.html - ASM Flags
http://www.cavestory.org/guides/csasm/guide/asm_flags.html - Status Register
https://en.wikipedia.org/wiki/Status_register - Linux assemblers: A comparison of GAS and NASM
http://www.ibm.com/developerworks/library/l-gas-nasm/index.html - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - Is it worthwhile to learn x86 assembly language today?
https://www.quora.com/Is-it-worthwhile-to-learn-x86-assembly-language-today?share=1 - Why Learn Assembly Language?
http://www.codeproject.com/Articles/89460/Why-Learn-Assembly-Language - Is Assembly still relevant?
http://programmers.stackexchange.com/questions/95836/is-assembly-still-relevant - Why Learning Assembly Language Is Still a Good Idea
http://www.onlamp.com/pub/a/onlamp/2004/05/06/writegreatcode.html - Assembly language today
http://beust.com/weblog/2004/06/23/assembly-language-today/ - Assembler: Význam assembleru dnes
http://www.builder.cz/rubriky/assembler/vyznam-assembleru-dnes-155960cz - Programming from the Ground Up Book – Summary
http://savannah.nongnu.org/projects/pgubook/ - DOSBox
https://www.dosbox.com/ - The C Programming Language
https://en.wikipedia.org/wiki/The_C_Programming_Language - Hercules Graphics Card (HCG)
https://en.wikipedia.org/wiki/Hercules_Graphics_Card - Complete 8086 instruction set
https://content.ctcd.edu/courses/cosc2325/m22/docs/emu8086ins.pdf - Complete 8086 instruction set
https://yassinebridi.github.io/asm-docs/8086_instruction_set.html - 8088 MPH by Hornet + CRTC + DESiRE (final version)
https://www.youtube.com/watch?v=hNRO7lno_DM - Area 5150 by CRTC & Hornet (Party Version) / IBM PC+CGA Demo, Hardware Capture
https://www.youtube.com/watch?v=fWDxdoRTZPc - 80×86 Integer Instruction Set Timings (8088 – Pentium)
http://aturing.umcs.maine.edu/~meadow/courses/cos335/80×86-Integer-Instruction-Set-Clocks.pdf - Colour Graphics Adapter: Notes
https://www.seasip.info/VintagePC/cga.html - Restoring A Vintage CGA Card With Homebrew HASL
https://hackaday.com/2024/06/12/restoring-a-vintage-cga-card-with-homebrew-hasl/ - Demoing An 8088
https://hackaday.com/2015/04/10/demoing-an-8088/ - Video Memory Layouts
http://www.techhelpmanual.com/89-video_memory_layouts.html - Screen Attributes
http://www.techhelpmanual.com/87-screen_attributes.html - IBM PC Family – BIOS Video Modes
https://www.minuszerodegrees.net/video/bios_video_modes.htm - EGA Functions
https://cosmodoc.org/topics/ega-functions/#the-hierarchy-of-the-ega - Why the EGA can only use 16 of its 64 colours in 200-line modes
https://www.reenigne.org/blog/why-the-ega-can-only-use-16-of-its-64-colours-in-200-line-modes/ - How 16 colors saved PC gaming – the story of EGA graphics
https://www.custompc.com/retro-tech/ega-graphics - List of 16-bit computer color palettes
https://en.wikipedia.org/wiki/List_of16-bit_computer_color_palettes - Why were those colors chosen to be the default palette for 256-color VGA?
https://retrocomputing.stackexchange.com/questions/27994/why-were-those-colors-chosen-to-be-the-default-palette-for-256-color-vga - VGA Color Palettes
https://www.fountainware.com/EXPL/vga_color_palettes.htm - Hardware Level VGA and SVGA Video Programming Information Page
http://www.osdever.net/FreeVGA/vga/vga.htm - Hardware Level VGA and SVGA Video Programming Information Page – sequencer
http://www.osdever.net/FreeVGA/vga/seqreg.htm - VGA Basics
http://www.brackeen.com/vga/basics.html - Introduction to VGA Mode ‚X‘
https://web.archive.org/web/20160414072210/http://fly.srk.fer.hr/GDM/articles/vgamodex/vgamx1.html - VGA Mode-X
https://web.archive.org/web/20070123192523/http://www.gamedev.net/reference/articles/article356.asp - Mode-X: 256-Color VGA Magic
https://downloads.gamedev.net/pdf/gpbb/gpbb47.pdf - Instruction Format in 8086 Microprocessor
https://www.includehelp.com/embedded-system/instruction-format-in-8086-microprocessor.aspx - How to use „AND,“ „OR,“ and „XOR“ modes for VGA Drawing
https://retrocomputing.stackexchange.com/questions/21936/how-to-use-and-or-and-xor-modes-for-vga-drawing - VGA Hardware
https://wiki.osdev.org/VGA_Hardware - Programmer's Guide to Yamaha YMF 262/OPL3 FM Music Synthesizer
https://moddingwiki.shikadi.net/wiki/OPL_chip - Does anybody understand how OPL2 percussion mode works?
https://forum.vcfed.org/index.php?threads/does-anybody-understand-how-opl2-percussion-mode-works.60925/ - Yamaha YMF262 OPL3 music – MoonDriver for OPL3 DEMO [Oscilloscope View]
https://www.youtube.com/watch?v=a7I-QmrkAak - Yamaha OPL vs OPL2 vs OPL3 comparison
https://www.youtube.com/watch?v=5knetge5Gs0 - OPL3 Music Crockett's Theme
https://www.youtube.com/watch?v=HXS008pkgSQ - Bad Apple (Adlib Tracker – OPL3)
https://www.youtube.com/watch?v=2lEPH6Y3Luo - FM Synthesis Chips, Codecs and DACs
https://www.dosdays.co.uk/topics/fm_synthesizers.php - The Zen Challenge – YMF262 OPL3 Original (For an upcoming game)
https://www.youtube.com/watch?v=6JlFIFz1CFY - [adlib tracker II techno music – opl3] orbit around alpha andromedae I
https://www.youtube.com/watch?v=YqxJCu_WFuA - [adlib tracker 2 music – opl3 techno] hybridisation process on procyon-ii
https://www.youtube.com/watch?v=daSV5mN0sJ4 - Hyper Duel – Black Rain (YMF262 OPL3 Cover)
https://www.youtube.com/watch?v=pu_mzRRq8Ho - IBM 5155–5160 Technical Reference
https://www.minuszerodegrees.net/manuals/IBM/IBM_5155_5160_Technical_Reference_6280089_MAR86.pdf - a ymf262/opl3+pc speaker thing i made
https://www.youtube.com/watch?v=E-Mx0lEmnZ0 - [OPL3] Like a Thunder
https://www.youtube.com/watch?v=MHf06AGr8SU - (PC SPEAKER) bad apple
https://www.youtube.com/watch?v=LezmKIIHyUg - Powering devices from PC parallel port
http://www.epanorama.net/circuits/lptpower.html - Magic Mushroom (demo pro PC s DOSem)
http://www.crossfire-designs.de/download/articles/soundcards//mushroom.rar - Píseň Magic Mushroom – originál
http://www.crossfire-designs.de/download/articles/soundcards/speaker_mushroom_converted.mp3 - Píseň Magic Mushroom – hráno na PC Speakeru
http://www.crossfire-designs.de/download/articles/soundcards/speaker_mushroom_speaker.mp3 - Pulse Width Modulation (PWM) Simulation Example
http://decibel.ni.com/content/docs/DOC-4599 - Resistor/Pulse Width Modulation DAC
http://www.k9spud.com/traxmod/pwmdac.php - Class D Amplifier
http://en.wikipedia.org/wiki/Electronic_amplifier#Class_D - Covox Speech Thing / Disney Sound Source (1986)
http://www.crossfire-designs.de/index.php?lang=en&what=articles&name=showarticle.htm&article=soundcards/&page=5 - Covox Digital-Analog Converter (Rusky, obsahuje schémata)
http://phantom.sannata.ru/konkurs/netskater002.shtml - PC-GPE on the Web
http://bespin.org/~qz/pc-gpe/ - Keyboard Synthesizer
http://www.solarnavigator.net/music/instruments/keyboards.htm - FMS – Fully Modular Synthesizer
http://fmsynth.sourceforge.net/ - Javasynth
http://javasynth.sourceforge.net/ - Software Sound Synthesis & Music Composition Packages
http://www.linux-sound.org/swss.html - Mx44.1 Download Page (software synthesizer for linux)
http://hem.passagen.se/ja_linux/ - Software synthesizer
http://en.wikipedia.org/wiki/Software_synthesizer - Frequency modulation synthesis
http://en.wikipedia.org/wiki/Frequency_modulation_synthesis - Yamaha DX7
http://en.wikipedia.org/wiki/Yamaha_DX7 - Wave of the Future
http://www.wired.com/wired/archive/2.03/waveguides_pr.html - Analog synthesizer
http://en.wikipedia.org/wiki/Analog_synthesizer - Minimoog
http://en.wikipedia.org/wiki/Minimoog - Moog synthesizer
http://en.wikipedia.org/wiki/Moog_synthesizer - Tutorial for Frequency Modulation Synthesis
http://www.sfu.ca/~truax/fmtut.html - An Introduction To FM
http://ccrma.stanford.edu/software/snd/snd/fm.html - John Chowning
http://en.wikipedia.org/wiki/John_Chowning - I'm Impressed, Adlib Music is AMAZING!
https://www.youtube.com/watch?v=PJNjQYp1ras - Milinda- Diode Milliampere ( OPL3 )
https://www.youtube.com/watch?v=oNhazT5HG0E - Dune 2 – Roland MT-32 Soundtrack
https://www.youtube.com/watch?v=kQADZeB-z8M - Interrupts
https://wiki.osdev.org/Interrupts#Types_of_Interrupts - Assembly8086SoundBlasterDmaSingleCycleMode
https://github.com/leonardo-ono/Assembly8086SoundBlasterDmaSingleCycleMode/blob/master/sbsc.asm - Interrupts in 8086 microprocessor
https://www.geeksforgeeks.org/interrupts-in-8086-microprocessor/ - Interrupt Structure of 8086
https://www.eeeguide.com/interrupt-structure-of-8086/ - A20 line
https://en.wikipedia.org/wiki/A20_line - Extended memory
https://en.wikipedia.org/wiki/Extended_memory#eXtended_Memory_Specification_(XMS) - Expanded memory
https://en.wikipedia.org/wiki/Expanded_memory - Protected mode
https://en.wikipedia.org/wiki/Protected_mode - Virtual 8086 mode
https://en.wikipedia.org/wiki/Virtual_8086_mode - Unreal mode
https://en.wikipedia.org/wiki/Unreal_mode - DOS memory management
https://en.wikipedia.org/wiki/DOS_memory_management - Upper memory area
https://en.wikipedia.org/wiki/Upper_memory_area - Removing the Mystery from SEGMENT : OFFSET Addressing
https://thestarman.pcministry.com/asm/debug/Segments.html - Segment descriptor
https://en.wikipedia.org/wiki/Segment_descriptor - When using a 32-bit register to address memory in the real mode, contents of the register must never exceed 0000FFFFH. Why?
https://stackoverflow.com/questions/45094696/when-using-a-32-bit-register-to-address-memory-in-the-real-mode-contents-of-the - A Brief History of Unreal Mode
https://www.os2museum.com/wp/a-brief-history-of-unreal-mode/ - Segment Limits
https://wiki.osdev.org/Segment_Limits - How do 32 bit addresses in real mode work?
https://forum.osdev.org/viewtopic.php?t=30642 - The LOADALL Instruction by Robert Collins
https://www.rcollins.org/articles/loadall/tspec_a3_doc.html - How do you put a 286 in Protected Mode?
https://retrocomputing.stackexchange.com/questions/7683/how-do-you-put-a-286-in-protected-mode - Control register
https://en.wikipedia.org/wiki/Control_register - CPU Registers x86
https://wiki.osdev.org/CPU_Registers_x86 - x86 Assembly/Protected Mode
https://en.wikibooks.org/wiki/X86_Assembly/Protected_Mode - MSW: Machine Status Word
https://web.itu.edu.tr/kesgin/mul06/intel/intel_msw.html - 80×87 Floating Point Opcodes
http://www.techhelpmanual.com/876–80×87_floating_point_opcodes.html - Page Translation
https://pdos.csail.mit.edu/6.828/2005/readings/i386/s05_02.htm - 80386 Paging and Segmenation
https://stackoverflow.com/questions/38229741/80386-paging-and-segmenation - 80386 Memory Management
https://tldp.org/LDP/khg/HyperNews/get/memory/80386mm.html - DOSEMU
http://www.dosemu.org/ - Intel 80386, a revolutionary CPU
https://www.xtof.info/intel80386.html - PAI Unit 3 Paging in 80386 Microporcessor
https://www.slideshare.net/KanchanPatil34/pai-unit-3-paging-in-80386-microporcessor - 64 Terabytes of virtual memory for 32-bit x86 using segmentation: how?
https://stackoverflow.com/questions/5444984/64-terabytes-of-virtual-memory-for-32-bit-x86-using-segmentation-how - Pi in the Pentium: reverse-engineering the constants in its floating-point unit
http://www.righto.com/2025/01/pentium-floating-point-ROM.html - Simply FPU
http://www.website.masmforum.com/tutorials/fptute/ - Art of Assembly language programming: The 80×87 Floating Point Coprocessors
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–3.html - Art of Assembly language programming: The FPU Instruction Set
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–4.html - INTEL 80387 PROGRAMMER'S REFERENCE MANUAL
http://www.ragestorm.net/downloads/387intel.txt - x86 Instruction Set Reference: FLD
http://x86.renejeschke.de/html/file_module_x86_id100.html - x86 Instruction Set Reference: FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ
http://x86.renejeschke.de/html/file_module_x86_id101.html - X86 Assembly/Arithmetic
https://en.wikibooks.org/wiki/X86_Assembly/Arithmetic - 8087 Numeric Data Processor
https://www.eeeguide.com/8087-numeric-data-processor/ - Data Types and Instruction Set of 8087 co-processor
https://www.eeeguide.com/data-types-and-instruction-set-of-8087-co-processor/ - 8087 instruction set and examples
https://studylib.net/doc/5625221/8087-instruction-set-and-examples - GCC documentation: Extensions to the C Language Family
https://gcc.gnu.org/onlinedocs/gcc/C-Extensions.html#C-Extensions - GCC documentation: Using Vector Instructions through Built-in Functions
https://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Bulldozer (microarchitecture)
https://en.wikipedia.org/wiki/Bulldozer_(microarchitecture) - MMX (instruction set)
https://en.wikipedia.org/wiki/MMX_(instruction_set) - Extended MMX
https://en.wikipedia.org/wiki/Extended_MMX - Saturation arithmetic
https://en.wikipedia.org/wiki/Saturation_arithmetic - CMPPS — Compare Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/cmpps - ADDPS — Add Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/addps - SUBPS — Subtract Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/subps - SQRTPS — Square Root of Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/sqrtps - RSQRTPS — Compute Reciprocals of Square Roots of Packed Single Precision Floating-PointValues
https://www.felixcloutier.com/x86/rsqrtps - UNPCKHPS — Unpack and Interleave High Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/unpckhps - UNPCKLPS — Unpack and Interleave Low Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/unpcklps - SHUFPS — Packed Interleave Shuffle of Quadruplets of Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/shufps - CVTSI2SS — Convert Doubleword Integer to Scalar Single Precision Floating-Point Value
https://www.felixcloutier.com/x86/cvtsi2ss - CVTSS2SI — Convert Scalar Single Precision Floating-Point Value to Doubleword Integer
https://www.felixcloutier.com/x86/cvtss2si - CVTTSS2SI — Convert With Truncation Scalar Single Precision Floating-Point Value to Integer
https://www.felixcloutier.com/x86/cvttss2si - CVTPI2PS — Convert Packed Dword Integers to Packed Single Precision Floating-Point Values
https://www.felixcloutier.com/x86/cvtpi2ps - CVTPS2PI — Convert Packed Single Precision Floating-Point Values to Packed Dword Integers
https://www.felixcloutier.com/x86/cvtps2pi - CVTTPS2PI — Convert With Truncation Packed Single Precision Floating-Point Values to PackedDword Integers
https://www.felixcloutier.com/x86/cvttps2pi - Streaming SIMD Extensions 2 (SSE2)
https://softpixel.com/~cwright/programming/simd/sse2.php


